Anybody speaking even with the slightest of accents knows the agony that is talking to voice recognition systems. I ran head-long into this issue, when I recently tried to use voice commands with my computer. Both systems I tested, the NSSPeechRecognizer API of OSX and CMU Sphinx, failed miserably when confronted with my German accent. Slightly annoyed by this experience, I wondered, would it be really that hard to create a customized solution from scratch? As it turns out, not really, as I hope to convince you in the following paragraphs.
But first, let me summarize the goal of this project: building a system that continuously listens for a small number of pre-defined keywords and performs actions once these keywords are detected. To start, I chose three keywords, "explain", "stop", and "wait".
The first issues I ran into was how to capture audio with python. After a bit of research, I settled on python-sounddevice. It makes capturing audio as simple as:
import time
import sounddevice as sd
def callback(indata, outdata, frames, time, status):
# The callback will be called in regular intervals.
# indata is a numpy array of audio data recorded.
...
with sd.Stream(callback=callback):
time.sleep(24 * 60 * 60)
With this issue solved, I turned to how to approach the problem from a modelling perspective. While there are end-to-end methods to detect speech in continuous audio signals, it seemed somewhat overkill. Since I am only interested in isolated words, the problem can be simplified quite a lot by pre-processing the data to extract regions of interest. This step serves two purposes: First, it turns the problem into a series of simple sequence classification tasks. Second, it splits the input into much smaller segments that are easier to process. Consider the following example. It spans eight seconds in total, but each region of interest is only approximately one second long.
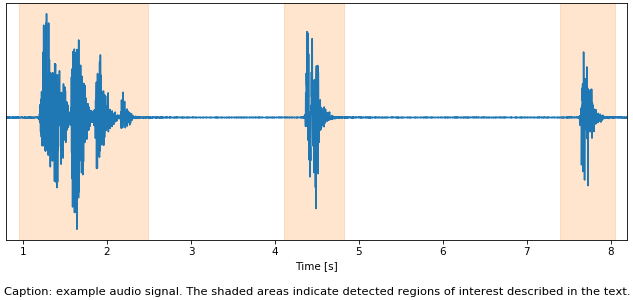
Here, I am a simple heuristic based on short-time averages of the signal intensity. If the mean intensity at any point in time is high enough, that point is considered of interest, as are any other points within a small time window. The only tricky part was to write the algorithm in such a way that it worked with blocks of audio that are not necessarily aligned with the regions of interest. To handle this issue, the algorithm buffers blocks as long as it is inside a region of interest. Once outside that region the algorithm stops buffering and emits the buffered data.
With short samples of potential keyword matches extracted, I was faced with the question of what kind of model to use for classification. Quite early I settled on a purely supervised model, since this problem is one of those where Richard Socher's advice applies ("Rather than spending a month figuring out an unsupervised machine learning problem, just label some data for a week and train a classifier"): First, I do not have that much training data to begin with, about 1000 samples, since I collected all data from scratch. Second, I found labeling with a suitable interface to be extremely efficient. Labeling 100 samples took about 4 minutes. That is less than an hour for the complete data set.
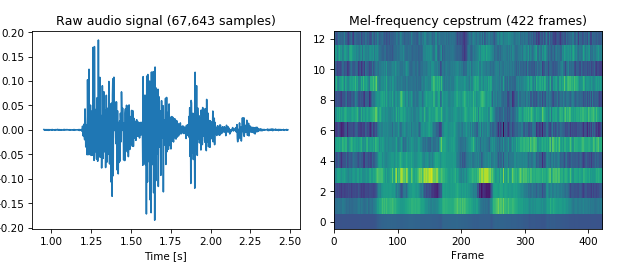
Instead of using raw audio signals, I opted to encode the data as Mel-frequency cepstrum coefficients. This encoding supplies frequency information directly and also shortens the sequences considerably. Computing the coefficients is as simple as calling a function thanks to python-speech-features. For the first region of interest the result looks as follows.
The model itself is a neural network with a mixture of convolutional and recurrent layers implemented in tensorflow. Specifically, the model is built as two stacks of dilated and non-dilated convolutions, with their outputs pooled by a recurrent layer. The final state of this recurrent layer if further transformed by a dense layer with softmax activation to obtain class probabilities. All parameters are optimized jointly with ADAM.

So, does it work? Actually, it does. Even the first attempt converged pretty rapidly and worked sufficiently well in first tests. Only when varying the distance to the microphone, misclassification became an issue. That problem however solved itself after half an hour of walking around in the room and shouting keywords at my computer. Another problem that came up were false positives. A lot of words are quite similar to keywords, e.g., remain and explain. As before, my solution to this problem was to collect more training data.
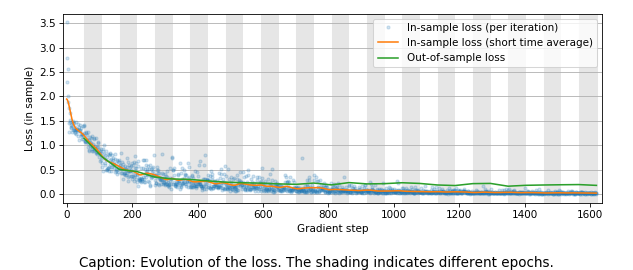
Training converges quite rapidly, with the loss leveling off after about eight epochs. Initially, the out-of sample loss trails the in-sample loss quite closely. After a while however, the model starts to slightly overfit and the loss curves start to diverge.
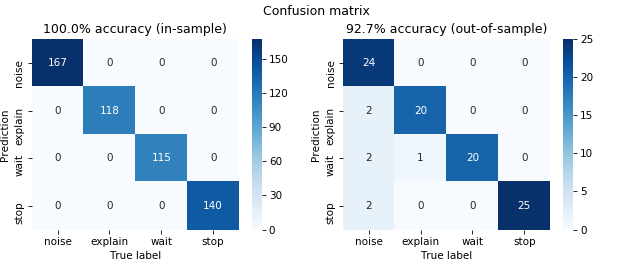
Looking at the confusion matrix in and out of sample also hints at overfitting with the in-sample accuracy reaching 100 % in contrast to 92 % out of-sample. Interestingly almost all misclassifications are restricted to the noise class. In practice however, performance is good enough for now, without any tuning. Therefore, I test the model properly in the wild, before revisiting the modeling part.
All in all, this project was surprisingly straight-forward. It took me about three evenings without any major surprises. This project also confirmed for me that purely supervised methods are king, if labeling data is not prohibitive. In this case, the time invested to build a proper interface for labeling data clearly payed off. This project also showed me again, that heuristics can get you a long way by simplifying the problem, reducing model complexity, and reducing the amount of data required.
Having said this, there are clear avenues for future improvements: as always, the first step will be to collect more data. To this end, I wrote the program such that it saves all samples collected during recognition. Further, it would be interesting to see how the model performs when adding more classes, since being restricted to three keywords is somewhat limiting. With more data collected, I will also revisit the optimization of the model via regularization, hyper-parameter tuning, and different architectures. Finally, I plan to look into semi-supervised learning, once the number of samples becomes so large that labeling them all is no longer feasible.
In case I sparked your interest, you can find the full code on github.
While I did not include the audio samples in the repository, it does include all
code used to collect them. If you have any questions or comments, I would love
to hear from you on twitter (@c_prohm).